Introduction to Hierarchical Linear Models / Mixed Effects Models in R
Before we start
You can find this guide and more on my github page.
This guide was designed as a friendly approach to learn how to conduct statistical analysis within the R environment. R is a powerful open-source tool that allows for great flexibility and customization of when conducting data wrangling (cleaning), analysis, interpretation, and reporting. Did I mention its open-source? This not only means that it is free, but the entire code used to develop this exceptional language is entirely available for you to view (and even suggest changes) online.
Several assumptions about the user will be made within this guide.
- You have installed R and an IDE such as RStudio or Visual Studio Code on your computer
- You have a dataset to work with
If these assumptions are not met, here are a few guides to reference that will get you up to speed
- Installing RStudio
- Exporting SPSS dataset to .CSV
- Exporting STATA dataset to .csv
- Exporting Excel file to .csv
Mixed Effects Models - What are they and how can we use them?
In educational research, it is common to collect data from multiple participants or classrooms. These data often exhibit nested or hierarchical structures, where individuals are nested within higher-level units (e.g., students within classrooms, classrooms within schools). In such cases, traditional statistical models assume independence of observations, which may lead to biased estimates of the parameters.
Mixed effects models, also known as hierarchical linear models (HLM), are statistical models that take into account the nested structure of the data and allow for the estimation of both fixed and random effects. Fixed effects are the parameters of interest that are assumed to be constant across all the individuals or units, while random effects capture the variability across individuals or units.
Using mixed effects models can improve the accuracy of the estimates, increase statistical power, and provide a more comprehensive understanding of the underlying processes in educational research. In this tutorial, we will use the R programming language to illustrate the basics of mixed effects modeling. We will use the lme4 package, which is one of the most popular packages for fitting mixed effects models in R.
Generating our Dataset
Using randomly-generated data, let’s build a fictitious dataset to math the scenario above and that we will use to run our HLM Model.
::: {.callout-warning appearance=“simple”}
This step is only required for the instructional nature of this tutorial. You will not need to run this step as you do not need to randomly generate your data. Unless you do… in which case, have at it!
:::
In the code block below, we will generate a dataframe consisting of math scores from students nested within classrooms who received an intervention of some kind and their respective SES. The purpose of this example is to determine whether the intervention had an effect on math scores, while controlling for SES, and taking into account the nested structure of the data.
::: {.cell}
# Generate sample data
set.seed(123)
n_classrooms <- 12
n_students <- 10
math_score_ctrl <- rnorm(n_classrooms*n_students, mean = 50, sd = 10)
math_score_trt <- rnorm(n_classrooms*n_students, mean = 55, sd = 7) # higher mean and smaller SD
math_score <- c(math_score_ctrl, math_score_trt)
ses <- c(rnorm(n_classrooms*n_students, mean = 50, sd = 10))
intervention <- rep(c(0,1), each = n_classrooms*n_students/2)
classroom_id <- rep(1:n_classrooms, each = n_students*2)
student_id <- rep(1:(n_students*2), times = n_classrooms)
# Create data frame
data <- data.frame(math_score, intervention, classroom_id, student_id, ses)
# Show first few rows
head(data)
::: {.cell-output .cell-output-stdout}
math_score intervention classroom_id student_id ses
1 44.39524 0 1 1 42.11378
2 47.69823 0 1 2 44.97801
3 65.58708 0 1 3 64.96061
4 50.70508 0 1 4 38.62696
5 51.29288 0 1 5 48.20948
6 67.15065 0 1 6 69.02362
::: :::
Exploring our Data
Let’s take a look at simple descriptive statisitcs within our data. Running the base (summary) command allows us to look at information such as the minimum, maximum, quartiles, median, and means for each variable within our dataset. You can further customize this command by adding further adjustments to the command itself. For example, if we want to run5 a summary command on just 1 or 2 variables within a dataset containing many other variables, we can adjust our code to specify which variables we are interested in by adding a $ symbol after the name of the dataset and then specifying the name of the variable (i.e., summary(df$intervention). Below we have run a simple summary command to explore our generated dataset. Since we only generated two variables, we do not need to specify which variables we are interested in.
::: {.cell}
summary(data)
::: {.cell-output .cell-output-stdout}
math_score intervention classroom_id student_id ses
Min. :26.91 Min. :0.0 Min. : 1.00 Min. : 1.00 Min. :25.34
1st Qu.:46.89 1st Qu.:0.0 1st Qu.: 3.75 1st Qu.: 5.75 1st Qu.:44.67
Median :52.27 Median :0.5 Median : 6.50 Median :10.50 Median :50.61
Mean :52.49 Mean :0.5 Mean : 6.50 Mean :10.50 Mean :50.86
3rd Qu.:57.83 3rd Qu.:1.0 3rd Qu.: 9.25 3rd Qu.:15.25 3rd Qu.:58.46
Max. :77.69 Max. :1.0 Max. :12.00 Max. :20.00 Max. :75.71
::: :::
Some summary information may not be necessarily useful (e.g., classroom_id and student_id). When analyzing nested data, we can leverage the dplyr package to group students by classroom and then calculate descriptive data. The dplyr package is a powerful tool that allows us to conduct data wrangling (cleaning) and analysis. In the code block below, we will use the dplyr package to group our students by classroom and then calculate the number of students per classroom and the mean and standard deviation of their math scores. Additionally, we will use the describeBy function from the psych package to calculate descriptive statistics for each intervention group.
::: {.cell}
# Load dplyr and psych package
library(dplyr)
library(psych)
# Group students by classroom and calculate the number of students per classroom
data %>%
group_by(classroom_id) %>%
summarise(n = n()) %>%
ungroup()
::: {.cell-output .cell-output-stdout}
# A tibble: 12 × 2
classroom_id n
<int> <int>
1 1 20
2 2 20
3 3 20
4 4 20
5 5 20
6 6 20
7 7 20
8 8 20
9 9 20
10 10 20
11 11 20
12 12 20
:::
# Group students by classroom and calculate mean and standard deviation
data %>%
group_by(classroom_id) %>%
summarise(mean = mean(math_score), sd = sd(math_score)) %>%
ungroup()
::: {.cell-output .cell-output-stdout}
# A tibble: 12 × 3
classroom_id mean sd
<int> <dbl> <dbl>
1 1 51.4 9.73
2 2 49.5 8.30
3 3 51.1 9.57
4 4 48.8 9.73
5 5 53.8 8.29
6 6 46.4 7.01
7 7 54.7 7.60
8 8 53.8 7.22
9 9 56.2 7.51
10 10 54.1 6.38
11 11 55.4 7.27
12 12 54.7 5.74
:::
data %>%
describeBy(group = "classroom_id")
::: {.cell-output .cell-output-stdout}
Descriptive statistics by group
classroom_id: 1
vars n mean sd median trimmed mad min max range skew
math_score 1 20 51.42 9.73 51.20 51.60 8.70 30.33 67.87 37.54 -0.06
intervention 2 20 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 NaN
classroom_id 3 20 1.00 0.00 1.00 1.00 0.00 1.00 1.00 0.00 NaN
student_id 4 20 10.50 5.92 10.50 10.50 7.41 1.00 20.00 19.00 0.00
ses 5 20 49.77 9.64 48.54 49.33 8.53 34.67 69.02 34.35 0.47
kurtosis se
math_score -0.55 2.17
intervention NaN 0.00
classroom_id NaN 0.00
student_id -1.38 1.32
ses -0.78 2.16
------------------------------------------------------------
classroom_id: 2
vars n mean sd median trimmed mad min max range skew
math_score 1 20 49.49 8.30 48.60 49.78 11.29 33.13 62.54 29.41 -0.19
intervention 2 20 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 NaN
classroom_id 3 20 2.00 0.00 2.00 2.00 0.00 2.00 2.00 0.00 NaN
student_id 4 20 10.50 5.92 10.50 10.50 7.41 1.00 20.00 19.00 0.00
ses 5 20 52.09 9.58 50.82 52.19 8.70 32.43 72.93 40.50 0.04
kurtosis se
math_score -1.21 1.86
intervention NaN 0.00
classroom_id NaN 0.00
student_id -1.38 1.32
ses -0.23 2.14
------------------------------------------------------------
classroom_id: 3
vars n mean sd median trimmed mad min max range skew
math_score 1 20 51.06 9.57 49.64 50.79 7.79 34.51 71.69 37.18 0.31
intervention 2 20 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 NaN
classroom_id 3 20 3.00 0.00 3.00 3.00 0.00 3.00 3.00 0.00 NaN
student_id 4 20 10.50 5.92 10.50 10.50 7.41 1.00 20.00 19.00 0.00
ses 5 20 53.95 9.81 51.95 54.40 9.74 33.33 70.02 36.70 -0.24
kurtosis se
math_score -0.60 2.14
intervention NaN 0.00
classroom_id NaN 0.00
student_id -1.38 1.32
ses -0.63 2.19
------------------------------------------------------------
classroom_id: 4
vars n mean sd median trimmed mad min max range skew
math_score 1 20 48.80 9.73 47.88 48.78 8.20 26.91 70.50 43.59 0.04
intervention 2 20 1.00 0.00 1.00 1.00 0.00 1.00 1.00 0.00 NaN
classroom_id 3 20 4.00 0.00 4.00 4.00 0.00 4.00 4.00 0.00 NaN
student_id 4 20 10.50 5.92 10.50 10.50 7.41 1.00 20.00 19.00 0.00
ses 5 20 49.61 11.38 47.71 49.52 13.02 29.86 70.38 40.52 0.11
kurtosis se
math_score -0.04 2.18
intervention NaN 0.00
classroom_id NaN 0.00
student_id -1.38 1.32
ses -1.13 2.54
------------------------------------------------------------
classroom_id: 5
vars n mean sd median trimmed mad min max range skew
math_score 1 20 53.75 8.29 53.59 53.40 9.78 39.74 71.87 32.14 0.32
intervention 2 20 1.00 0.00 1.00 1.00 0.00 1.00 1.00 0.00 NaN
classroom_id 3 20 5.00 0.00 5.00 5.00 0.00 5.00 5.00 0.00 NaN
student_id 4 20 10.50 5.92 10.50 10.50 7.41 1.00 20.00 19.00 0.00
ses 5 20 50.50 9.98 51.22 50.98 10.29 29.48 65.19 35.71 -0.42
kurtosis se
math_score -0.79 1.85
intervention NaN 0.00
classroom_id NaN 0.00
student_id -1.38 1.32
ses -0.93 2.23
------------------------------------------------------------
classroom_id: 6
vars n mean sd median trimmed mad min max range skew
math_score 1 20 46.41 7.01 46.36 46.61 7.08 33.32 59.19 25.87 -0.09
intervention 2 20 1.00 0.00 1.00 1.00 0.00 1.00 1.00 0.00 NaN
classroom_id 3 20 6.00 0.00 6.00 6.00 0.00 6.00 6.00 0.00 NaN
student_id 4 20 10.50 5.92 10.50 10.50 7.41 1.00 20.00 19.00 0.00
ses 5 20 49.26 12.00 50.11 49.21 8.87 25.34 75.71 50.37 0.00
kurtosis se
math_score -0.84 1.57
intervention NaN 0.00
classroom_id NaN 0.00
student_id -1.38 1.32
ses -0.19 2.68
------------------------------------------------------------
classroom_id: 7
vars n mean sd median trimmed mad min max range skew
math_score 1 20 54.73 7.60 54.89 54.56 7.22 40.63 68.36 27.74 0.15
intervention 2 20 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 NaN
classroom_id 3 20 7.00 0.00 7.00 7.00 0.00 7.00 7.00 0.00 NaN
student_id 4 20 10.50 5.92 10.50 10.50 7.41 1.00 20.00 19.00 0.00
ses 5 20 49.77 9.64 48.54 49.33 8.53 34.67 69.02 34.35 0.47
kurtosis se
math_score -0.83 1.70
intervention NaN 0.00
classroom_id NaN 0.00
student_id -1.38 1.32
ses -0.78 2.16
------------------------------------------------------------
classroom_id: 8
vars n mean sd median trimmed mad min max range skew
math_score 1 20 53.79 7.22 53.10 53.53 10.03 43.79 69.70 25.91 0.21
intervention 2 20 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 NaN
classroom_id 3 20 8.00 0.00 8.00 8.00 0.00 8.00 8.00 0.00 NaN
student_id 4 20 10.50 5.92 10.50 10.50 7.41 1.00 20.00 19.00 0.00
ses 5 20 52.09 9.58 50.82 52.19 8.70 32.43 72.93 40.50 0.04
kurtosis se
math_score -0.90 1.62
intervention NaN 0.00
classroom_id NaN 0.00
student_id -1.38 1.32
ses -0.23 2.14
------------------------------------------------------------
classroom_id: 9
vars n mean sd median trimmed mad min max range skew
math_score 1 20 56.17 7.51 55.36 55.14 5.08 46.18 77.69 31.51 1.18
intervention 2 20 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 NaN
classroom_id 3 20 9.00 0.00 9.00 9.00 0.00 9.00 9.00 0.00 NaN
student_id 4 20 10.50 5.92 10.50 10.50 7.41 1.00 20.00 19.00 0.00
ses 5 20 53.95 9.81 51.95 54.40 9.74 33.33 70.02 36.70 -0.24
kurtosis se
math_score 1.33 1.68
intervention NaN 0.00
classroom_id NaN 0.00
student_id -1.38 1.32
ses -0.63 2.19
------------------------------------------------------------
classroom_id: 10
vars n mean sd median trimmed mad min max range skew
math_score 1 20 54.07 6.38 53.04 53.53 6.23 45.82 68.98 23.16 0.63
intervention 2 20 1.00 0.00 1.00 1.00 0.00 1.00 1.00 0.00 NaN
classroom_id 3 20 10.00 0.00 10.00 10.00 0.00 10.00 10.00 0.00 NaN
student_id 4 20 10.50 5.92 10.50 10.50 7.41 1.00 20.00 19.00 0.00
ses 5 20 49.61 11.38 47.71 49.52 13.02 29.86 70.38 40.52 0.11
kurtosis se
math_score -0.54 1.43
intervention NaN 0.00
classroom_id NaN 0.00
student_id -1.38 1.32
ses -1.13 2.54
------------------------------------------------------------
classroom_id: 11
vars n mean sd median trimmed mad min max range skew
math_score 1 20 55.42 7.27 52.62 54.93 5.41 46.01 70.39 24.38 0.62
intervention 2 20 1.00 0.00 1.00 1.00 0.00 1.00 1.00 0.00 NaN
classroom_id 3 20 11.00 0.00 11.00 11.00 0.00 11.00 11.00 0.00 NaN
student_id 4 20 10.50 5.92 10.50 10.50 7.41 1.00 20.00 19.00 0.00
ses 5 20 50.50 9.98 51.22 50.98 10.29 29.48 65.19 35.71 -0.42
kurtosis se
math_score -0.97 1.63
intervention NaN 0.00
classroom_id NaN 0.00
student_id -1.38 1.32
ses -0.93 2.23
------------------------------------------------------------
classroom_id: 12
vars n mean sd median trimmed mad min max range skew
math_score 1 20 54.73 5.74 54.04 54.34 5.96 45.78 68.69 22.91 0.58
intervention 2 20 1.00 0.00 1.00 1.00 0.00 1.00 1.00 0.00 NaN
classroom_id 3 20 12.00 0.00 12.00 12.00 0.00 12.00 12.00 0.00 NaN
student_id 4 20 10.50 5.92 10.50 10.50 7.41 1.00 20.00 19.00 0.00
ses 5 20 49.26 12.00 50.11 49.21 8.87 25.34 75.71 50.37 0.00
kurtosis se
math_score -0.40 1.28
intervention NaN 0.00
classroom_id NaN 0.00
student_id -1.38 1.32
ses -0.19 2.68
::: :::
Great! It looks like we have 10 students per classroom and their mean math scores range between 45 and 55. Also, thanks to the psych package, we get detailed group-level descriptive statistics for each classroom.
Let’s visualize this information using a histogram. To do this, we can use the ggplot2 package. This package allows us to create beautiful and informative data visualizations. In the code block below, we will use the ggplot2 package to create a histogram of our math scores. Also, let’s bring in the facet_wrap function to create a histogram for each intervention group.
::: {.cell}
# Load ggplot2 package
library(ggplot2)
# Plot histogram
ggplot(data, aes(x = math_score)) +
geom_histogram(binwidth = 5) +
facet_wrap(~intervention)
::: {.cell-output-display}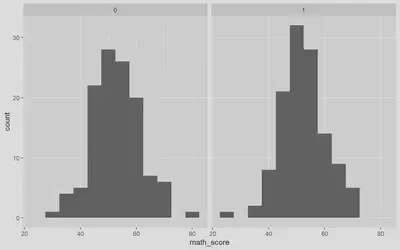
This histogram shows us that the math scores for both intervention groups are normally distributed. However, the mean math score for the intervention group is slightly higher than the control group.
Centering our Data
According to best practices, we want to mean and grand mean center our data before running our mixed effects model. This is because centering our data allows us to interpret the intercept as the mean of the outcome variable when all predictors are at their mean. In the code block below, we will use the MLMusingR and misty package to mean and grand mean center our data.
::: {.cell}
library(MLMusingR) #using for centering
library(misty) #used for grand mean centering
# Creating Group Means for SES
data <- data %>%
group_by(classroom_id) %>%
mutate(ses_grpmean = mean(ses)) %>%
ungroup()
# Group mean centering SES
data <- data %>%
mutate(ses_mc = group_center(ses, classroom_id))
data$ses_mc <- as.numeric(data$ses_mc)
# Grand mean centering Gender
data <- data %>%
mutate(ses_gmc = center(ses_grpmean, type = "CGM", cluster = classroom_id))
:::
When mean centering our data within the context of HLM, our mean centered variable is the difference between the individual score and the group mean. For example, if a student’s SES score is 60 and the mean SES score for their classroom is 50, then the mean centered SES score for that student is 10.
When grand mean centering our data within the context of HLM, our grand mean centered variable is the difference between the group mean and the grand mean. For example, if the mean SES score for a classroom is 50 and the grand mean SES score for the entire sample is 45, then the grand mean centered SES score for that classroom is 5.
Here’s how your dataframe should look like up to this point:
::: {.cell}
head(data)
::: {.cell-output .cell-output-stdout}
# A tibble: 6 × 8
math_score intervention classroom_id student_id ses ses_grpmean ses_mc
<dbl> <dbl> <int> <int> <dbl> <dbl> <dbl>
1 44.4 0 1 1 42.1 49.8 -7.65
2 47.7 0 1 2 45.0 49.8 -4.79
3 65.6 0 1 3 65.0 49.8 15.2
4 50.7 0 1 4 38.6 49.8 -11.1
5 51.3 0 1 5 48.2 49.8 -1.56
6 67.2 0 1 6 69.0 49.8 19.3
# ℹ 1 more variable: ses_gmc <dbl>
::: :::
Running our Model
Now that we have explored our data and centered our variables, we are ready to run our HLM model. In the code block below, we will use the lme4 package to run our models. The lme4 package is a powerful tool that allows us to run mixed effects models and has a similar syntax to the lm function. The lmerTest package is an extension of the lme4 package and allows us to run significance tests for our models.
Null Model
::: {.cell}
# Load lme4 package
library(lme4)
library(lmerTest)
# Run null model
null_model <- lmer(math_score ~ 1 + (1 | classroom_id), data = data)
summary(null_model)
::: {.cell-output .cell-output-stdout}
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: math_score ~ 1 + (1 | classroom_id)
Data: data
REML criterion at convergence: 1687
Scaled residuals:
Min 1Q Median 3Q Max
-2.91013 -0.69522 -0.07367 0.58727 2.86313
Random effects:
Groups Name Variance Std.Dev.
classroom_id (Intercept) 5.987 2.447
Residual 63.379 7.961
Number of obs: 240, groups: classroom_id, 12
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 52.4855 0.8735 11.0000 60.09 3.36e-15 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
::: :::
In this model, we are predicting math scores using a random intercept for classroom. The random intercept for classroom is represented by (1 | classroom_id). The 1 represents the intercept and the classroom_id represents the groups.
Now, let’s run our full model. We want to see if the intervention has an effect on math scores while controlling for SES. We also want to see if the intervention has a different effect on math scores for students with low SES compared to students with high SES. We will allow the intervention vary across classrooms.
Full Model
::: {.cell}
# Run full model
full_model <- lmer(math_score ~ intervention + ses + intervention*ses + (1 + intervention | classroom_id), data = data)
summary(full_model)
::: {.cell-output .cell-output-stdout}
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula:
math_score ~ intervention + ses + intervention * ses + (1 + intervention |
classroom_id)
Data: data
REML criterion at convergence: 1685.7
Scaled residuals:
Min 1Q Median 3Q Max
-2.88198 -0.65425 -0.08606 0.59275 2.80765
Random effects:
Groups Name Variance Std.Dev. Corr
classroom_id (Intercept) 3.477 1.865
intervention 3.199 1.789 0.56
Residual 62.655 7.915
Number of obs: 240, groups: classroom_id, 12
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 61.07409 4.08533 198.58309 14.950 <2e-16 ***
intervention -9.71573 5.46709 201.25036 -1.777 0.0771 .
ses -0.15977 0.07602 230.57755 -2.102 0.0367 *
intervention:ses 0.17658 0.10097 229.31073 1.749 0.0816 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr) intrvn ses
interventin -0.747
ses -0.966 0.722
intrvntn:ss 0.728 -0.942 -0.753
::: :::
In this model, we are predicting math scores using intervention, SES, and the interaction between intervention and SES. We are also allowing the intercept and intervention to vary across classrooms. The random intercept and intervention for classroom is represented by (1 + intervention | classroom_id).
Israel Arevalo
Research Scientist
Provisional Licensed Psychologist
Bilingual School Psychologist
I am a research scientist and bilingual school psychologist at Texas A&M Health Telehealth Institute.